 14 Stream API
14 Stream API
# Stream
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。 使用 Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。 也可以使用 Stream API 来并行执行操作。简言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
# 为什么要使用 Stream API
- 实际开发中,项目中多数数据源都来自于 Mysql,Oracle 等。但现在数据源可以更多了,有 MongDB,Radis 等,而这些 NoSQL 的数据就需要 Java 层面去处理。
- Stream 和 Collection 集合的区别:Collection 是一种静态的内存数据结构,而 Stream 是有关计算的。前者是主要面向内存,存储在内存中, 后者主要是面向 CPU,通过 CPU 实现计算。
Java 8 的 Lambda 让我们可以更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行了对比说明。结合集合中遍历操作,可以发现循环遍历的弊端:
- for 循环的语法就是“怎么做”
- for 循环的循环体才是“做什么”
如果希望对集合中的元素进行筛选过滤:
- 将集合 A 根据条件一过滤为子集 B;
- 然后再根据条件二过滤为子集 C。
使用线性循环就意味着只能遍历一次,那么需多次循环来解决;并且循环是做事情的方式,而不是目的。
//筛选以张开始,长度为3,遍历打印
list.stream()
.filter(s->s.startsWith("张"))
.filter(s->s.length()==3)
.forEach(s -> System.out.println(s));
2
3
4
5
# 流式思想概述
整体来看,流式思想类似于工厂车间的“生产流水线”。当需要对多个元素进行操作(特别是多步操作)的时候,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤方案,然后再按照方案去执行它。
这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而右侧的数字 3 是终结果。
这里的 filter 、 map 、 skip 都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法 count 执行的时候,整个模型才会按照指定策略执行操作。而这得益于Lambda 的延迟执行特性。
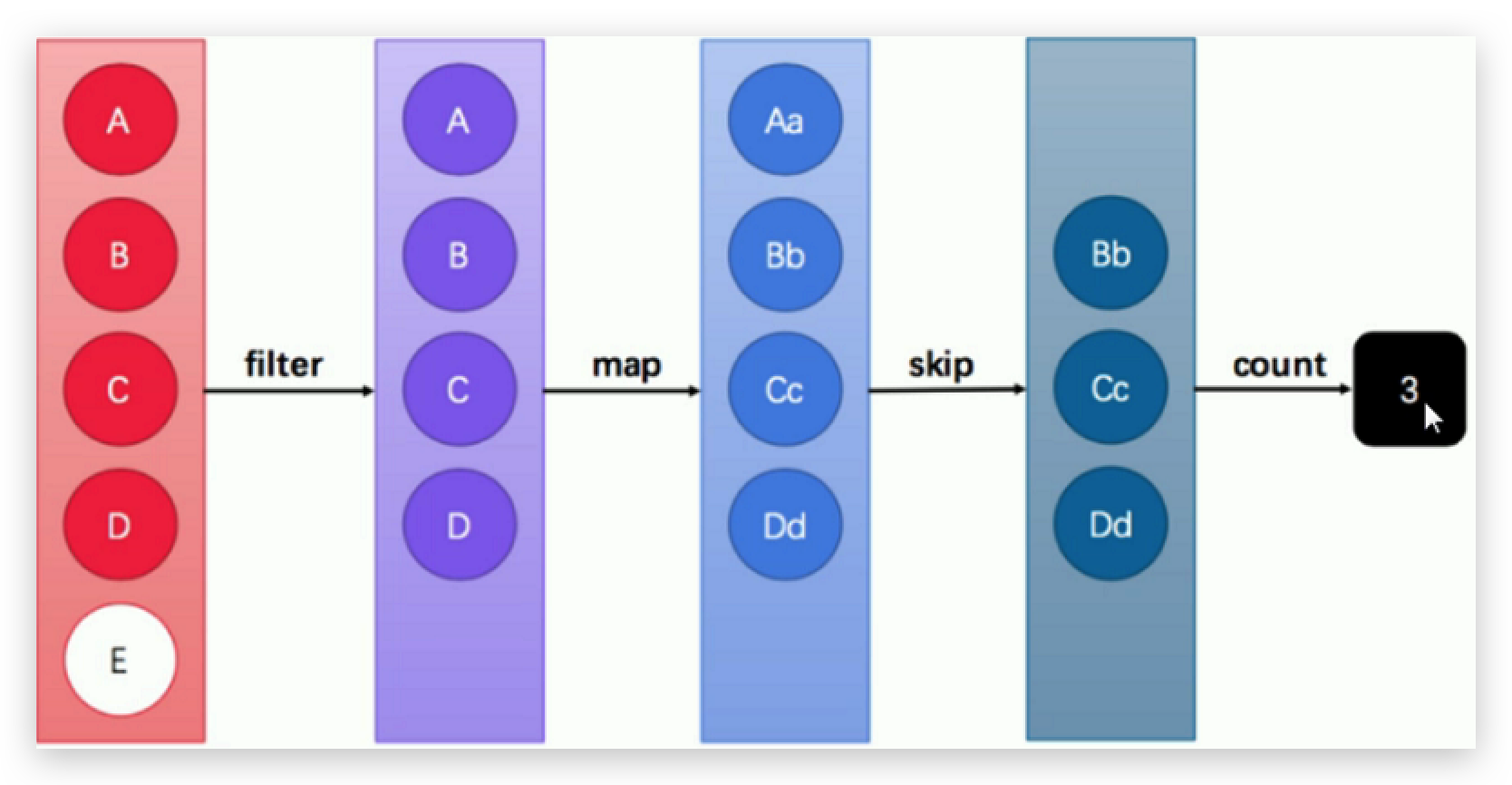
Stream 流其实是一个集合元素的函数模型,它并不是集合,也不是数据结构。
和以前的 Collection 操作不同, Stream 操作还有几个基础的特征:
- 其本身并不存储任何元素(或其地址值),而是按需计算。
- Pipelining:中间操作都会返回流对象本身,且不改变原对象。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 并可以对操作进行优化, 比如延迟执行(laziness)和短路(short-circuiting)。
- 内部迭代:以前对集合遍历都是通过 Iterator 或者增强 for 的方式,显式的在集合外部进行迭代, 这叫做外部迭代。 Stream 提供了内部迭代的方式,流可以直接调用遍历方法。
# Stream 的操作三个步骤
- 创建 Stream:从一个数据源(如集合、数组),获取一个流
- 中间操作:一个中间操作链,对数据源的数据进行处理
- 终止操作(终端操作):一旦执行终止操作,就执行中间操作链,并产生结果,之后 Stream 不能再被使用
# 创建 Stream 的方法
# Stream.of
通过Stream类的静态方法of(),通过显示值创建一个流。它可以接收任意数量的参数。
public static<T> Stream<T> of(T... values): 返回一个流
# Stream.iterate/generate
通过Stream类的静态方法创建无限流(了解)
迭代
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)Stream<Integer> stream = Stream.iterate(0, x -> x + 2); stream.limit(10).forEach(System.out::println);// 遍历前10个1
2生成
public static<T> Stream<T> generate(Supplier<T> s)Stream<Double> stream1 = Stream.generate(Math::random); stream1.limit(10).forEach(System.out::println);// 生成随机数10个1
2
# Arrays.stream 🔥
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流
static <T> Stream<T> stream(T[] array):返回一个流重载形式,能够处理对应基本类型的数组:
public static IntStream stream(int[] array)public static LongStream stream(long[] array)public static DoubleStream stream(double[] array)
# collection.stream 🔥
Java8 中的 Collection 接口被扩展,提供了两个获取流的普通成员方法
default Stream<E> stream():返回一个顺序流default Stream<E> parallelStream():返回一个并行流;stream.parallel()也可以获取并行流
# Stream 的中间操作
Stream 属于管道流,只能被使用一次,数据从上一个 Stream 传到下一个 Stream 上,上一个 Stream 已经关闭。多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理,而在终止操作时一次性全部处理,称为“惰性求值(延迟方法)”。
# 筛选与切片
filter(Predicate p)接收 Lambda, 从流中排除过滤某些元素
limit(long maxSize)截断流,使其元素不超过给定数量,截取前 maxSize 个
skip(long n)返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与
limit(n)互补distinct()筛选,通过流所生成元素的
hashCode()和equals()去除重复元素@Test public void test1(){ List<Employee> list = EmployeeData.getEmployees(); //filter(Predicate p)——接收 Lambda , 从流中排除某些元素。 // 每次都需要重新获取 Stream //练习:查询员工表中薪资大于7000的员工信息 list.stream();.filter(e -> e.getSalary() > 7000).forEach(System.out::println); //limit(n)——截断流,使其元素不超过给定数量。 list.stream().limit(3).forEach(System.out::println); //skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补 list.stream().skip(3).forEach(System.out::println); //distinct()——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素 list.add(new Employee(1010,"刘强东",40,8000)); list.add(new Employee(1010,"刘强东",41,8000)); list.add(new Employee(1010,"刘强东",40,8000)); list.add(new Employee(1010,"刘强东",40,8000)); list.add(new Employee(1010,"刘强东",40,8000)); list.stream().distinct().forEach(System.out::println); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 映射
map(Function f)接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。mapToDouble(ToDoubleFunction f)接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。mapToInt(ToIntFunction f)接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。mapToLong(ToLongFunction f)接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。flatMap(Function f)接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流,类似 List 中的addAll()方法@Test public void test2(){ // map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。 List<String> list = Arrays.asList("aa", "bb", "cc", "dd"); list.stream().map(str -> str.toUpperCase()).forEach(System.out::println); // 练习1:获取员工姓名长度大于3的员工的姓名。 List<Employee> employees = EmployeeData.getEmployees(); Stream<String> namesStream = employees.stream().map(Employee::getName); namesStream.filter(name -> name.length() > 3).forEach(System.out::println); // ----------------------------------------------------- //练习2: Stream<Stream<Character>> streamStream = list.stream().map(StreamAPITest1::fromStringToStream); streamStream.forEach(s ->{ s.forEach(System.out::println); }); // flatMap(Function f)——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。 Stream<Character> characterStream = list.stream().flatMap(StreamAPITest1::fromStringToStream); characterStream.forEach(System.out::println); } //将字符串中的多个字符构成的集合转换为对应的Stream的实例 public static Stream<Character> fromStringToStream(String str){//aa ArrayList<Character> list = new ArrayList<>(); for(Character c : str.toCharArray()){ list.add(c); } return list.stream(); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 排序
sorted()产生一个新流,按自然顺序排序sorted(Comparator com)产生一个新流,按比较器顺序排序
# Stream 的终止操作
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void 。流进行了终止操作后,不能再次使用。
# 匹配与查找
boolean allMatch(Predicate p)检查是否匹配所有元素boolean anyMatch(Predicate p)检查是否至少匹配一个元素boolean noneMatch(Predicate p)检查是否没有匹配所有元素Optional<T> findFirst()返回第一个元素Optional<T> findAny()返回当前流中的任意元素long count()返回流中元素总数Optional<T> max(Comparator c)返回流中最大值Optional<T> min(Comparator c)返回流中最小值void forEach(Consumer c)内部迭代(使用 Collection 接口需要用户去做迭代称为外部迭代。相反 Stream API 使用内部迭代——它帮你把迭代做了)@Test public void test1(){ List<Employee> employees = EmployeeData.getEmployees(); // allMatch(Predicate p)——检查是否匹配所有元素。 // 练习:是否所有的员工的年龄都大于18 boolean allMatch = employees.stream().allMatch(e -> e.getAge() > 18); System.out.println(allMatch); // anyMatch(Predicate p)——检查是否至少匹配一个元素。 // 练习:是否存在员工的工资大于 10000 boolean anyMatch = employees.stream().anyMatch(e -> e.getSalary() > 10000); System.out.println(anyMatch); // noneMatch(Predicate p)——检查是否没有匹配的元素。 // 练习:是否存在员工姓“雷” boolean noneMatch = employees.stream().noneMatch(e -> e.getName().startsWith("雷")); System.out.println(noneMatch); // findFirst——返回第一个元素 Optional<Employee> employee = employees.stream().findFirst(); System.out.println(employee); // findAny——返回当前流中的任意元素 Optional<Employee> employee1 = employees.parallelStream().findAny(); System.out.println(employee1); } @Test public void test2(){ List<Employee> employees = EmployeeData.getEmployees(); // count——返回流中元素的总个数 long count = employees.stream().filter(e -> e.getSalary() > 5000).count(); System.out.println(count); // max(Comparator c)——返回流中最大值 // 练习:返回最高的工资: Stream<Double> salaryStream = employees.stream().map(e -> e.getSalary()); Optional<Double> maxSalary = salaryStream.max(Double::compare); System.out.println(maxSalary); // min(Comparator c)——返回流中最小值 // 练习:返回最低工资的员工 Optional<Employee> employee = employees.stream().min((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())); System.out.println(employee); // forEach(Consumer c)——内部迭代 employees.stream().forEach(System.out::println); //使用集合的遍历操作 employees.forEach(System.out::println); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 归约
reduce(T iden, BinaryOperator b)可以将流中元素反复结合起来,得到一个值,返回T,iden为初始值reduce(BinaryOperator b)可以将流中元素反复结合起来,得到一个值。返回Optional<T>map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名。
@Test public void test3(){ // reduce(T identity, BinaryOperator)——可以将流中元素反复结合起来,得到一个值。返回 T // 练习1:计算1-10的自然数的和 List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10); Integer sum = list.stream().reduce(0, Integer::sum);// 0 为初始值 System.out.println(sum);// 55 // reduce(BinaryOperator) ——可以将流中元素反复结合起来,得到一个值。返回 Optional<T> // 练习2:计算公司所有员工工资的总和 List<Employee> employees = EmployeeData.getEmployees(); Stream<Double> salaryStream = employees.stream().map(Employee::getSalary); Optional<Double> sumMoney = salaryStream.reduce(Double::sum); // Optional<Double> sumMoney = salaryStream.reduce((d1,d2) -> d1 + d2); System.out.println(sumMoney.get()); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 收集
collect(Collector c)将流转换为其他形式。接收一个Collector接口的实现,用于给Stream中元素做汇总的方法。Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、 Map)。另外,Collectors实用类提供了很多静态方法,可以方便地创建常见收集器实例, 具体方法与实例如下表:static List<T> toList把流中元素收集到 List
List<Employee> emps= list.stream().collect(Collectors.toList());1static Set<T> toSet把流中元素收集到 Set
Set<Employee> emps= list.stream().collect(Collectors.toSet());1static Collection<T> toCollection把流中元素收集到创建的集合
Collection<Employee> emps =list.stream().collect(Collectors.toCollection(ArrayList::new));1Object[] toArray()转为数组,返回包含此流的元素的数组
//略1<A> A[] toArray(IntFunction<A[]> generator)通过方法引用指定创建数组类型如
String[]::new// 略1static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)合并流
Stream<String> one2 = one.stream().filter(name -> name.length() == 3).limit(3); Stream<String> two2 = two.stream().filter(name -> name.startsWith("张")).skip(2); Stream.concat(one2, two2).map(name -> new Person(name)).forEach(name -> System.out.println(name));1
2
3Long counting计算流中元素的个数
long count = list.stream().collect(Collectors.counting());1Integer summingInt对流中元素的整数属性求和
int total=list.stream().collect(Collectors.summingInt(Employee::getSalary));1Double averagingInt计算流中元素 Integer 属性的平均值
double avg = list.stream().collect(Collectors.averagingInt(Employee::getSalary));1IntSummaryStatistics summarizingInt收集流中 Integer 属性的统计值。如平均值
int SummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getSalary));1String joining([CharSequence delimiter])连接流中每个字符串
注意,使用
delimiter时要确定map中数据类型String str= list.stream().map(Employee::getName).collect(Collectors.joining());1Optional<T> maxBy根据比较器选择最大值
Optional<Emp>max= list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary)));1Optional<T> minBy根据比较器选择最小值
Optional<Emp> min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary)));1归约产生的类型 reducing从一个作为累加器的初始值开始, 利用 BinaryOperator 与流中元素逐个结合,从而归约成单个值
int total=list.stream().collect(Collectors.reducing(0, Employee::getSalar, Integer::sum));1转换函数返回的类型 collectingAndThen包裹另一个收集器,对其结果转换函数
int how= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size));1Map<K, List<T>> groupingBy根据某属性值对流分组,属性为 K 结果为 V
Map<Emp.Status, List<Emp>> map= list.stream() .collect(Collectors.groupingBy(Employee::getStatus));1Map<Boolean, List<T>> partitioningBy根据 true 或 false 进行分区
Map<Boolean,List<Emp>> vd = list.stream().collect(Collectors.partitioningBy(Employee::getManage));1@Test public void test4(){ // collect(Collector c)——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法 // 练习1:查找工资大于6000的员工,结果返回为一个List或Set List<Employee> employees = EmployeeData.getEmployees(); List<Employee> employeeList = employees.stream().filter(e -> e.getSalary() >6000).collect(Collectors.toList()); employeeList.forEach(System.out::println); System.out.println(); Set<Employee> employeeSet = employees.stream().filter(e -> e.getSalary() > 6000).collect(Collectors.toSet()); employeeSet.forEach(System.out::println); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 习题
# 返回一个由每个数的平方 🔥
给定一个数字列表,如何返回一个由每个数的平方构成的列表呢?
例如,给定【1,2,3,4,5】, 应该返回【1,4,9,16,25】。
@Test
void test1() {
// ArrayList<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5));
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 长度不变,所以可以操作 Arrays.asList 生成的
List<Integer> list2 = list.stream().map(i -> i * i).collect(Collectors.toList());
System.out.println(list2);
}
2
3
4
5
6
7
8
9
# reduce & BinaryOperator🔥
怎样用 map 和 reduce 方法数一数流中有多少个 Employee 呢?
List<Employee> emps = Arrays.asList(
new Employee(102, "李四", 59, 6666.66, Status.BUSY),
new Employee(101, "张三", 18, 9999.99, Status.FREE),
new Employee(103, "王五", 28, 3333.33, Status.VOCATION),
new Employee(104, "赵六", 8, 7777.77, Status.BUSY),
new Employee(104, "赵六", 8, 7777.77, Status.FREE),
new Employee(104, "赵六", 8, 7777.77, Status.FREE),
new Employee(105, "田七", 38, 5555.55, Status.BUSY)
);
@Test
void test2() {
long count = emps.stream().count();
System.out.println(count);
// BinaryOperator 函数式接口使用,T apply(T t1, T t2)
Integer count2 = emps.stream().map(i -> 1).reduce(Integer::sum).get();
System.out.println(count2);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 交易操作 🔥
/**
* 交易员类
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Trader {
private String name;
private String city;
}
2
3
4
5
6
7
8
9
10
11
/**
* 交易类
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Transaction {
private Trader trader;
private int year;
private int value;
}
2
3
4
5
6
7
8
9
10
11
找出 2011 年发生的所有交易, 并按交易额排序(从低到高)
交易员都在哪些不同的城市工作过
查找所有来自剑桥的交易员,并按姓名排序
返回所有交易员的姓名字符串,按字母顺序排序
有没有交易员是在米兰工作的
打印生活在剑桥的交易员的所有交易额
所有交易中,最高的交易额是多少
找到交易额最小的交易
public class TransactionTest {
List<Transaction> transactions;
@BeforeEach
void setUp() {
Trader raoul = new Trader("Raoul", "Cambridge");
Trader mario = new Trader("Mario", "Milan");
Trader alan = new Trader("Alan", "Cambridge");
Trader brian = new Trader("Brian", "Cambridge");
transactions = Arrays.asList(
new Transaction(brian, 2011, 300),
new Transaction(raoul, 2012, 1000),
new Transaction(raoul, 2011, 400),
new Transaction(mario, 2012, 710),
new Transaction(mario, 2012, 700),
new Transaction(alan, 2012, 950)
);
}
/**
* 找出2011年发生的所有交易,并按交易额排序(从低到高)
*/
@Test
void test1() {
transactions
.stream()
.filter(transaction -> transaction.getYear() == 2011)
.sorted(Comparator.comparingInt(Transaction::getValue))
.forEach(System.out::println);
}
/**
* 交易员都在哪些不同的城市工作过
*/
@Test
void test2() {
transactions
.stream()
.map(transaction -> transaction.getTrader().getCity())
.distinct()
.forEach(System.out::println);
}
/**
* 查找所有来自剑桥的交易员,并按姓名排序
*/
@Test
void test3() {
transactions
.stream()
.filter(transaction -> "Cambridge".equals(transaction.getTrader().getCity()))
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted(String::compareTo)
.forEach(System.out::println);
}
/**
* 返回所有交易员的姓名字符串,按字母顺序排序
*/
@Test
void test4() {
transactions
.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted(String::compareTo)
.forEach(System.out::print);
// AlanBrianMarioRaoul
System.out.println();
String reduce = transactions
.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted(String::compareTo)
.reduce("", String::concat);
System.out.println(reduce);
// AlanBrianMarioRaoul
// 这个只是练习了下 flatMap 转换为流
transactions.stream()
.map((t) -> t.getTrader().getName())
.flatMap(TransactionTest::filterCharacter)
// .sorted(String::compareToIgnoreCase)
.forEach(System.out::print);
// BrianRaoulRaoulMarioMarioAlan
}
private static Stream<String> filterCharacter(String str){
List<String> list = new ArrayList<>();
for (Character ch : str.toCharArray()) {
list.add(ch.toString());
}
return list.stream();
}
/**
* 有没有交易员是在米兰工作的
*/
@Test
void test5() {
boolean b = transactions
.stream()
.anyMatch(transaction -> "Milan".equals(transaction.getTrader().getCity()));
System.out.println(b);
}
/**
* 打印生活在剑桥的交易员的所有交易额
*/
@Test
void test6() {
Optional<Integer> reduce = transactions
.stream()
.filter(transaction -> "Cambridge".equals(transaction.getTrader().getCity()))
.map(Transaction::getValue)
.reduce(Integer::sum);
System.out.println(reduce.orElse(0));
}
/**
* 所有交易中,最高的交易额是多少
*/
@Test
void test7() {
Optional<Integer> max = transactions
.stream()
.map(Transaction::getValue)
.max(Comparator.naturalOrder());// 自然排序
// .min(Comparator.reverseOrder());// 逆序
// .max(Integer::compare);
// .max(Integer::compareTo);
// .max(Comparator.comparingInt(o -> o));
System.out.println(max.orElse(0));
}
/**
* 找到交易额最小的交易
*/
@Test
void test8() {
Optional<Transaction> min = transactions
.stream()
.min(Comparator.comparingInt(Transaction::getValue));
System.out.println(min.orElse(null));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157