 列数据类型 🔥
列数据类型 🔥
# MySQL 列数据类型 🔥
# 数字类型
# 整数(精确值)🔥
很显然,使用的字节数越多,意味着能表示的数值范围就越大,但是也就越耗费存储空间。根据表示一个数占用字节数的不同,MySQL把整数划分成如下所示的类型:
| 类型 | 占用的字节 | 无符号数取值范围 | 有符号数取值范围 | 含义 |
|---|---|---|---|---|
TINYINT | 1 | 0 ~ 2⁸-1 0~255 | -2⁷ ~ 2⁷-1 -128~127 | 非常小的整数 |
标准 SQL:SMALLINT | 2 | 0 ~ 2¹⁶-1 0~65535 | -2¹⁵ ~ 2¹⁵-1 -32768~32767 | 小的整数 |
MEDIUMINT | 3 | 0 ~ 2²⁴-1 0~16777215 | -2²³ ~ 2²³-1 -8388608~8388607 | 中等大小的整数 |
标准 SQL:INT或别名INTEGER | 4 | 0 ~ 2³²-1 0~4294967295 | -2³¹ ~ 2³¹-1 -2147483648~2147483647 | 标准的整数 |
BIGINT | 8 | 0 ~ 2⁶⁴-1 | -2⁶³ ~ 2⁶³-1 | 大整数 |
以TINYINT为例,用 1 个字节,也就是 8 个位表示有符号数的话,就是既可以表示正数,也可以表示负数的话,需要有一个比特位表示正负号。但是如果表示无符号数的话,也就是只表示非负数的话,就不需要表示正负号,这是有符号数和无符号数的区别。
整数类型声明时如TINYINT(11)中11和占用字节无关,只是影响ZEROFILL,详细见DDL章节
# 浮点(不精确值)
提示
首先要明确:
无理数概念:也称为无限不循环小数,不能写作两整数之比。如 派,e 等。1/3 不是无理数!但是也不能用二进制表示
两有理数运算不会产生无理数(即使是 1/3)
待续...
# 引入—用二进制表示十进制小数
用二进制表示十进制小数
浮点数是用来表示小数的,我们平时用的十进制小数也可以被转换成二进制后被计算机存储。比如9.875,这个小数可以被表示成这样:
9.875 = 8 + 1 + 0.5 + 0.25 + 0.125 = 1 × 2³ + 1 × 2⁰ + 1 × 2⁻¹ + 1 × 2⁻² + 1 × 2⁻³
也就是说,如果十进制小数9.875转换成二进制小数的话就是:1001.111。为了在计算机里存储这种二进制小数,我们统一把它们表示成a × 2ⁿ的科学计数法的形式,其中 1≤|a|< 2(其首位数必然是 1,二进制嘛),比如1001.111可以被表示成1.001111 × 2³,我们把小数点之后的001111称为尾数,把2³中的3称为指数,然后只需要在计算机中的比特位中表示出尾数和指数就行了。另外,小数也有正负之分,我们还需要单独的部分来表示小数的正负号。综上所述,表示一个浮点数需要下边几个部分:
- 符号部分,占用 1 个比特位即可。
- 尾数部分,视具体浮点数格式而定。
- 指数部分,视具体浮点数格式而定。
# 浮点数类型
很显然,我们表示一个浮点数使用的字节数越多,表示尾数和指数的范围就越大,也就是说可以表示的小数范围就越大,设计MySQL的大叔根据表示一个小数需要的不同字节数定义了如下的两种浮点数类型:
| 类型 | 占用的存储空间(单位:字节) | 绝对值最小非 0 值 | 绝对值最大非 0 值 | 含义 |
|---|---|---|---|---|
FLOAT | 4 | ±1.175494351E-38 | ±3.402823466E+38 | 单精度浮点数 |
DOUBLE | 8 | ±2.2250738585072014E-308 | ±1.7976931348623157E+308 | 双精度浮点数 |
以单精度浮点数类型FLOAT类型为例,它占用的 4 个字节的各个组成部分如下图所示:
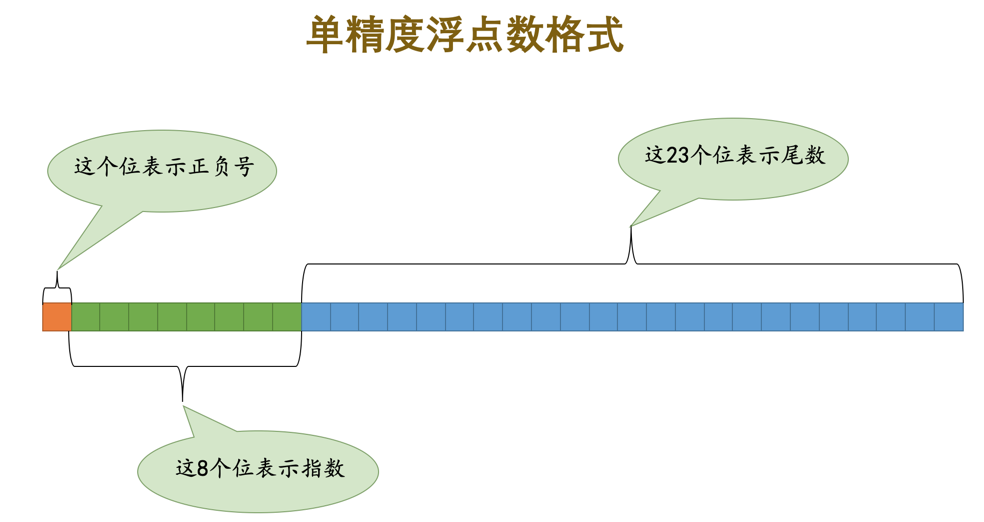
另外需要注意的是,虽然有的十进制小数,比如1.875可以被很容易的转换成二进制数1.111,但是更多的小数是无法直接转换成二进制的,比如说0.3,它转换成的二进制小数就是一个无限小数,但是我们现在只能用 4 个字节或者 8 个字节来表示这个小数,所以只能进行一些舍入来近似的表示,所以我们说计算机的浮点数表示有时是不精确的。
# 设置最大位数和小数位数
在定义浮点数类型时,还可以在FLOAT或者DOUBLE后边跟上两个参数,就像这样:
FLOAT(M, D)
DOUBLE(M, D)
2
对于我们用户而言,使用的都是十进制小数。如果我们事先知道表中的某个列要存储的小数在一定范围内,我们可以使用FLOAT(M, D)或者DOUBLE(M, D)来限制可以存储到本列中的小数范围。其中:
M表示该小数最多需要的十进制有效数字个数。注意是
有效数字个数,比方说对于小数-2.3来说有效数字个数就是 2,对于小数0.9来说有效数字个数就是1。D表示该小数的小数点后的十进制数字个数。这个好理解,小数点后有几个十进制数字,
D的值就是什么。
举个例子看一下,设置了M和D的单精度浮点数的取值范围的变化:
| 类型 | 取值范围 |
|---|---|
FLOAT(4, 1) | -999.9~999.9 |
FLOAT(5, 1) | -9999.9~9999.9 |
FLOAT(6, 1) | -99999.9~99999.9 |
FLOAT(4, 0) | -9999~9999 |
FLOAT(4, 1) | -999.9~999.9 |
FLOAT(4, 2) | -99.99~99.99 |
可以看到,在 D 相同的情况下,M 越大,该类型的取值范围越大;在 M 相同的情况下,D 越大,该类型的取值范围越小。当然,M和D的取值也不是无限大的,M的取值范围是1~255,D的取值范围是0~30,而且D的值必须不大于M。M和D都是可选的,如果我们省略了它们,那它们的值按照机器支持的最大值来存储。
# 定点(精确值)🔥
# 定点数类型
正因为用浮点数表示小数可能会有不精确的情况,在一些情况下我们必须保证小数是精确的,所以设计MySQL的大叔们提出一种称之为定点数的数据类型,它也是存储小数的一种方式:
| 类型 | 占用的存储空间(单位:字节) | 取值范围 |
|---|---|---|
DECIMAL(M, D) | 取决于 M 和 D | 取决于 M 和 D |
此处的M和D的含义与浮点数中的含义一样。M和D对取值范围的影响我们之前在唠叨浮点数的时候已经介绍过了,但是我们又说单精度浮点数类型FLOAT(M, D)占用的字节数一直都是 4 字节,双精度浮点数DOUBLE(M, D)占用的字节数一直都是 8 字节,它们占用的存储空间大小并不随着 M 和 D 的值的变动而变动,为啥到了这个所谓的定点数类型DECIMAL(M, D)中,它占用的存储空间大小就和M、D的取值有关了呢?哈哈,回答这个问题还得且听我细细道来。
# 分析
我们说定点数是一种精确的小数,为了达到精确的目的我们就不能把它转换成二进制小数之后再存储(因为有很多十进制小数转为二进制小数后需要进行舍入操作,导致二进制小数表示的数值是不精确的,如 0.3)。其实转念一想,所谓的小数只是把两个十进制整数用小数点分割开来而已,我们只要把小数点左右的两个十进制整数给存储起来,那不就是精确的了么。比方说对于十进制小数2.38来说,我们可以把这个小数的小数点左右的两个整数,也就是2和38分别保存起来,那么不就相当于保存了一个精确的小数么,这波操作是不是很 6。
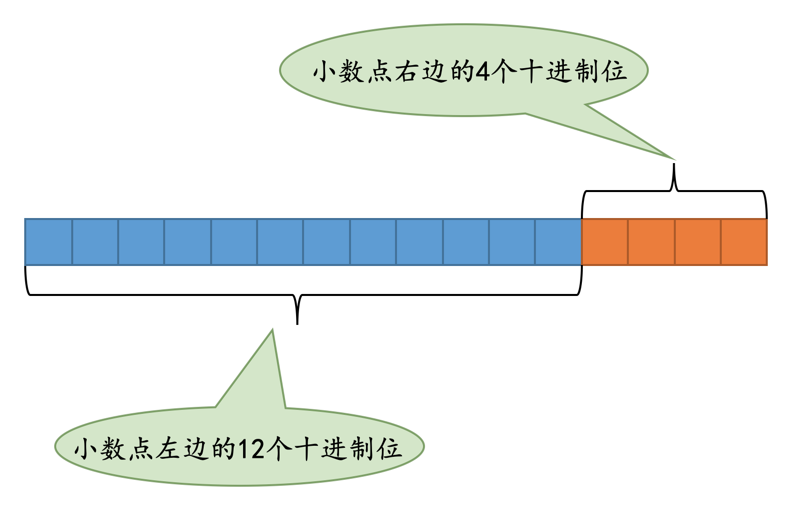
当然事情并没有这么简单,对于给定M、D值的DECIMAL(M, D)类型,比如DEMCIMAL(16, 4)来说:
首先确定小数点左边的整数最多需要存储的十进制位数是 12 位,小数点右边的整数需要存储的十进制位数是 4 位,如图所示:
从小数点位置出发,每个整数每隔 9 个十进制位划分为 1 组,效果就是这样:
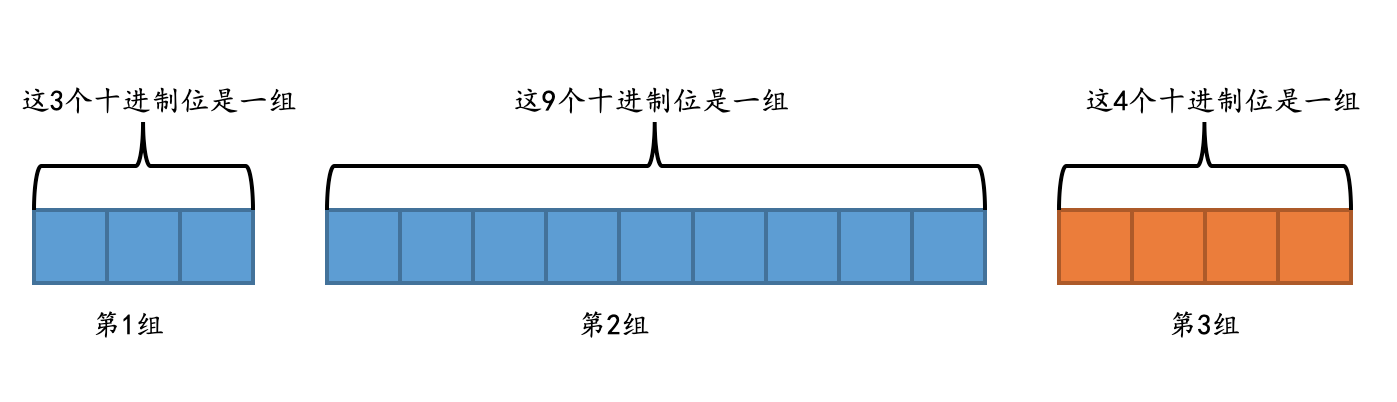
从图中可以看出,如果不足 9 个十进制位,也会被划分成一组。🔥
针对每个组中的十进制数字,将其转换为二进制数字进行存储,根据组中包含的十进制数字位数不同,所需的存储空间大小也不同,具体见下表:
组中包含的十进制位数 占用存储空间大小(单位:字节) 1 或 2(0 ~ 9,0 ~ 99,下同) 1 3 或 4(0 ~ 999,9999,下同) 2 5 或 6 3 7 或 8 或 9 4 所以
DECIMAL(16, 4)共需要占用8个字节的存储空间大小,这 8 个字节由下边 3 个部分组成:- 第 1 组包含 3 个十进制位,需要使用 2 个字节存储(这里是按照 16,4 划分的,别忘了!即使没有值也占用空间!)。
- 第 2 组包含 9 个十进制位,需要使用 4 个字节存储。
- 第 3 组包含 4 个十进制位,需要使用 2 个字节存储。
将转换完成的比特位序列的最高位设置为 1?为啥。
# 例子
这些步骤看的有一丢丢懵逼吧,别着急,举个例子就都清楚了。比方说我们使用定点数类型DECIMAL(16, 4)来存储十进制小数1234567890.1234,这个小数会被划分成 3 个部分:
1 234567890 1234
也就是:
- 第 1 组中包含整数
1。但是该组有 3 个十进制空间! - 第 2 组中包含整数
234567890。该组有 9 个十进制空间 - 第 3 组中包含整数
1234。该组有 4 个十进制空间
然后将每一组中的十进制数字转换成对应的二进制数字:
第 1 组占用 2 个字节,整数
1对应的二进制数就是(字节之间实际上没有空格,只不过为了大家理解上的方便我们加了一个空格)(这里是按照 16,4 划分的,别忘了!即使没有值也占用空间!)。:00000000 000000011二进制看起来太难受,我们还是转换成对应的十六进制看一下:
0x00011第 2 组占用 4 个字节,整数
234567890对应的十六进制数就是:0x0DFB38D21第 3 组占用 2 个字节,整数
1234对应的十六进制数就是:0x04D21
所以将这些十六进制数字连起来之后就是:
0x00010DFB38D204D2
最后还要将这个结果的最高位设置为 1,所以最终十进制小数1234567890.1234使用定点数类型DECIMAL(16, 4)存储时共占用 8 个字节,具体内容为:
0x80010DFB38D204D2
有的同学会问,如果我们想使用定点数类型DECIMAL(16, 4)存储一个负数怎么办,比方说-1234567890.1234,这时只需要将0x80010DFB38D204D2中的每一个比特位都执行一个取反操作就好,也就是得到下边这个结果:
0x7FFEF204C72DFB2D
从上边的叙述中我们可以知道,对于DECIMAL(M, D)类型来说,给定的M和D的值不同,所需的存储空间大小也不同。可以看到,与浮点数相比,定点数需要更多的空间来存储数据,所以如果不是在某些需要存储精确小数的场景下,一般的小数用浮点数表示就足够了。
对于定点数类型DECIMAL(M, D)来说,M和D都是可选的,默认的M的值是 10,默认的D的值是 0,也就是说下列等式是成立的:
DECIMAL = DECIMAL(10) = DECIMAL(10, 0)
DECIMAL(n) = DECIMAL(n, 0)
2
另外M的范围是1~65,D的范围是0~30,且D的值不能超过M。
# 无符号数值类型 🔥
对于数值类型,包括整数、浮点数和定点数,有些情况下我们只需要用到无符号数(就是非负数)。MySQL给我们提供了一个表示无符号数值类型的方式,就是在原数值类型后加一个单词UNSIGNED:
数值类型 UNSIGNED
大家可以把它当成一种新类型对待,比如INT UNSIGNED就表示无符号整数,FLOAT UNSIGNED表示无符号浮点数,DECIMAL UNSIGNED表示无符号定点数。
提示
在使用的存储空间大小相同的情况下,无符号整数可以表示的正整数范围比有符号整数能表示的正整数范围大一倍。不过受浮点数和定点数具体的存储格式影响,无符号浮点数和定点数并不能提升正数的表示范围。
# 日期和时间类型
# 简介
MySQL为我们提供了多种关于时间和日期的类型,各种类型能表示的范围如下(版本更新后又变了):
| 类型 | 存储空间要求(根据取值范围) | 取值范围 | 含义 |
|---|---|---|---|
YEAR(不用?) | 1 字节 | 1901~2155 | 年份值 |
DATE | 3 字节 | '1000-01-01' ~ '9999-12-31' | 日期值 |
TIME | 3 字节 | '-838:59:59' ~ '838:59:59' | 时间值 |
DATETIME | 8 字节 | '1000-01-01 00:00:00' ~ '9999-12-31 23:59:59' | 日期加时间值 |
TIMESTAMP | 4 字节 | '1970-01-01 00:00:01' ~ '2038-01-19 03:14:07' | 时间戳。若不给这个字段赋值,或赋值为 null,则默认使用当前系统时间 |
除了年月日之外,Oracle 中使用的 DATE 型还包含时分秒
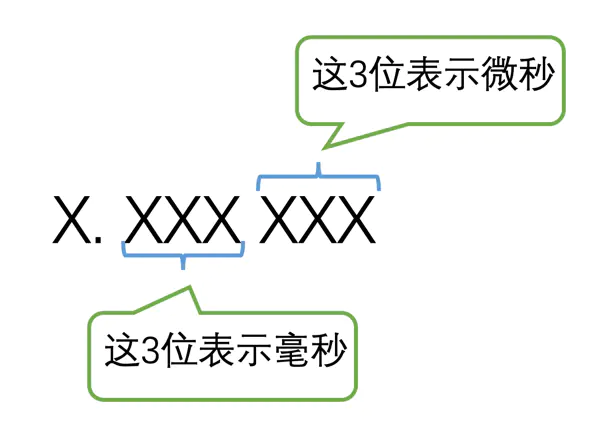
在MySQL5.6.4这个版本之后,TIME、DATETIME、TIMESTAMP这几种类型添加了对毫秒、微秒的支持。由于毫秒、微秒都不到 1 秒,所以也被称为小数秒,MySQL最多支持 6 位小数秒的精度,各个位代表的意思如下:
如果我们想让TIME、DATETIME、TIMESTAMP这几种类型支持小数秒,可以这样写:
类型(小数秒位数)
其中的小数秒位数可以在0、1、2、3、4、5、6中选择
2
3
比如DATETIME(0)表示精确到秒,DATETIME(3)表示精确到毫秒,DATETIME(5)表示精确到 10 微秒,DATETIME(6)表示精确到微秒。如果你在选择TIME、DATETIME、TIMESTAMP这几种类型的时候添加了对小数秒的支持,那么所需的存储空间需要相应的扩大,保留不同的小数秒位数,那么增加的存储空间大小也不同,如下表(同定点数需要空间一样,都是根据 10 进制位数计算出的):
| 保留的小数秒位数 | 额外需要的存储空间要 |
|---|---|
| 0 | 0 字节 |
| 1 或 2 | 1 字节 |
| 3 或 4 | 2 字节 |
| 5 或 6 | 3 字节 |
也就是说如果你选择使用DATETIME(1),那么需要的存储空间就是在DATETIME的空间上再加上小数秒需要的空间,就是8 + 1 = 9个字节,类似的,DATETIME(3)就需要8 + 2 = 10个字节。所以,MySQL5.6.4这个版本之后的各个类型需要的存储空间和取值范围就如下:
| 类型 | 存储空间要求(根据取值范围) | 取值范围 | 含义 |
|---|---|---|---|
YEAR | 1 字节 | 1901~2155 | 年份值 |
DATE | 3 字节 | '1000-01-01' ~ '9999-12-31' | 日期值 |
TIME | 3 字节+小数秒的存储空间 | '-838:59:59[.000000]' ~ '838:59:59[.000000]' | 时间值 |
DATETIME | 5 字节+小数秒的存储空间 | '1000-01-01 00:00:00[.000000]' ~ '9999-12-31 23:59:59'[.999999] | 日期加时间值 |
TIMESTAMP | 4 字节+小数秒的存储空间 | '1970-01-01 00:00:01[.000000]' ~ '2038-01-19 03:14:07'[.999999] | 时间戳。若不给这个字段赋值,或赋值为 null,则默认使用当前系统时间 |
大家应该发现其中的在没有存储小数秒的情况下,DATETIME类型占用的存储空间从原来的 8 字节变成了 5 字节,这是因为设计MySQL的大叔背后做了些努力,使存储格式变得更紧凑了些(在MySQL5.6.4这个版本之后)。
# YEAR
YEAR类型也可以写成YEAR(4),它单纯表示一个年份值,取值范围为1901 ~ 2155,仅仅占用 1 个字节大小而已。因为可以存储的年份值有限,如果我们想存储更大范围的年份值,可以不使用MySQL自带的YEAR类型,换成SMALLINT(2 字节)或者字符串类型啥的都可以。
小贴士: 曾经也有 YEAR(2)这种使用 2 个数字来表示年份的类型,比方说数字 99 表示 1999 年。不过在 MySQL 5.7.5 之后就不再支持这种类型了,我们稍微了解一下就好了。
# DATE、TIME 和 DATETIME
DATE表示日期,格式是YYYY-MM-DD;TIME表示时间,格式是hh:mm:ss[.uuuuuu]或者hhh:mm:ss[.uuuuuu](有时候要存储的小时值是三位数)DATETIME表示日期+时间,格式是YYYY-MM-DD hh:mm:ss[.uuuuuu]。其中的YYYY、MM、DD、hh、mm、ss、uuuuuu分别表示年、月、日、时、分、秒、小数秒。
需要注意的是,DATETIME中的时间部分表示的是一天内的时间(00:00:00 ~ 23:59:59),而 TIME 表示的是一段时间,而且可以表示负值(可用于存储计时)。
# TIMESTAMP
1970-01-01 00:00:00注定是一个特殊的时刻,我们把某个时刻距离1970-01-01 00:00:00的秒数称为时间戳。比方说当前时间是2018-01-24 11:39:21,距离1970-01-01 00:00:00的秒数为1516765161,那么2018-01-24 11:39:21这个时刻的时间戳就是1516765161。不过在MySQL5.6.4之后,时间戳的值也可以加入小数秒。
用时间戳存储时间的好处就是,它展示的值可以随着时区的变化而变化。比方说我们把2018-01-24 11:39:21这个时刻存储到一个TIMESTAMP的列中,那么在中国你看到的时间就是2018-01-24 11:39:21,如果你去了日本,他们哪里的使用的是东京时间,比北京时间早一个小时,所以他们那显示的就是2018-01-24 12:39:21。而如果你用DATETIME存储2018-01-24 11:39:21的话,那不同时区看到的时间值都是一样的。
# 总结
需要存储精确类型,可以使用 INT(BIGINT) UNSIGNED 存储时间戳即可
# 字符串类型
# 字符和字符串
字符可以大致分为两种,一种叫可见字符,一种叫不可见字符。顾名思义,可见字符就是打印出来后能看见的字符。比如'a','b','我','。' ... 这样的人眼能看见的单个的国家文字、标点符号、图形符号、数字等这样的东东,我们就叫做一个可见字符。不可见字符也好理解,就是打印机或者在黑框框里打印字符的时候有时候需要换行,打个制表符啥的,或者在输出某个字符的时候就发出嘟地一声,这种我们看不到,只是为了控制输出效果的字符叫做不可见字符。字符串就是把字符连起来的样子,比如'abc',就是由'a'、'b'、'c'三个字符连起来的一个字符串,下边列举了 4 个字符串的例子:
'我喜欢你'
'me, too'
'give me a hug'
'么么哒'
2
3
4
# 字符编码简介 🔥
在具体分析MySQL中各个字符串类型之前,我们一定要先搞明白字符和字节的区别。字符是面向人的概念,字节是面向计算机的概念。如果你想在计算机中表示字符,那就需要将该字符与一个特定的字节序列对应起来,这个映射过程称之为编码。不幸的是,这种映射关系并不是唯一的,不同的人制作了不同的编码方案,根据表示一个字符使用的字节数量是不是固定的,编码方案可以分为下边两种:
固定长度的编码方案
表示不同的字符所需要的字节数量是相同的。比方说
ASCII编码方案采用 1 个字节来编码一个字符,ucs2采用 2 个字节来编码一个字符。变长的编码方案
表示不同的字符所需要的字节数量是不同的。比方说
utf8编码方案采用1~3个字节来编码一个字符,gb2312采用1~2个字节来编码一个字符。
对于不同的字符编码方案来说,同一个字符可能被编码成不同的字节序列。比如同样一个字符:我,在utf8和gb2312这两种编码方案下被映射成如下的字节序列:
utf8 编码方案
字符
'我'被编码成:1110011010001000100100011共占用 3 个字节,用十六进制表示就是:
0xE68891。gb2312 编码方案
字符
'我'被编码成:11001110110100101共占用 2 个字节,用十六进制表示就是:
0xCED2。
小贴士: 注:十六进制前边的 0x 是前缀,表示后边的是 16 进制数据。
另外,设计 MySQL 的大叔似乎对编码方案和字符集这两个概念并没做什么区分,也就是说我们之后所讲的utf8字符集指的就是utf8编码方案,gb2312字符集指的也就是gb2312编码方案。
小贴士: 正宗的 utf8 字符集是使用 1~4 个字节来编码一个字符的,不过 MySQL 中对 utf8 字符集做了阉割,编码一个字符最多使用 3 个字节。如果我们之后有存储使用 4 个字节来编码的字符的情景,可以使用一种称之为utf8mb4 的字符集,它才是正宗的 utf8 字符集。
# 字符串类型总览 🔥
现在我们可以看一下MySQL中提供的各种字符串类型(注:其中M代表该数据类型最多能存储的字符数量,L代表我们实际向该类型的属性中存储的字符串在特定字符集下所占的字节数,W代表在该特定字符集下,编码一个字符最多需要的字节数):
| 类型 | 最大长度 | 存储空间要求 | 含义 |
|---|---|---|---|
CHAR(M) | M 个字符 | M×W 个字节 | 固定长度的字符串 |
VARCHAR(M) | M 个字符 | L+1 或 L+2 个字节 | 可变长度的字符串 |
TINYTEXT | 2⁸-1 个字节 | L+1 个字节 | 非常小型的字符串 |
TEXT | 2¹⁶-1 个字节 | L+2 个字节 | 小型的字符串 |
MEDIUMTEXT | 2²⁴-1 个字节 | L+3 个字节 | 中等大小的字符串 |
LONGTEXT | 2³²-1 个字节 | L+4 个字节 | 大型的字符串 |
当然,就画这么个表格大家一准儿有些懵,我们接下来看一下各种字符串类型的细节。
# CHAR(M)
总结:固定长度字符串类型,数据的长度不足指定长度,补空格到指定长度!取出时再把“右侧”空格删掉(即右侧本身有空格,则会丢失
CHAR(M)中的M代表该类型最多可以存储的字符数量,注意,是字符数量,不是字节数量。其中M的取值范围是0~255。如果省略掉M的值,那它的默认值就是 1,也就是说CHAR和CHAR(1)是一个意思。CHAR(0)是一种特别的类型,它只能存储空字符串''或者NULL值(我们后边会详细介绍啥是个NULL)。再回头看一眼我们的学生基本信息表,如果你觉得学生的姓名不会超过 5 个字符,你就可以指定这个姓名列的类型为CHAR(5)。
CHAR(M)在不同的字符集下需要的存储空间也是不一样的,我们假设某个字符集编码一个字符最多需要W个字节,那么类型CHAR(M)占用的存储空间大小就是M×W个字节。比方说:
- 对于采用
ascii字符集的CHAR(5)类型来说,ascii字符集编码一个字符最多需要 1 个字节,也就是M=5、W=1,所以这种情况下该类型占用的存储空间大小就是5×1 = 5个字节。 - 对于采用
gbk字符集的CHAR(5)类型来说,gbk字符集编码一个字符最多需要 2 个字节,也就是M=5、W=2,所以这种情况下该类型占用的存储空间大小就是5×2 = 10个字节。 - 对于采用
utf8字符集的CHAR(5)类型来说,utf8字符集编码一个字符最多需要 3 个字节,也就是M=5、W=3,所以这种情况下该类型占用的存储空间大小就是5×3 = 15个字节。
如果我们实际存储的字符串在特定字符集编码下占用的字节数不足M×W,那么剩余的那些存储空间用空格字符(也就是:' ')补齐。比方说表的某个属性的类型是采用ascii字符集的CHAR(5)类型,我们想将字符串'abc'存入使用这个类型的表属性中,其中字符串'abc'在ascii字符集下需要 3 个字节存储,而采用ascii字符集的CHAR(5)类型又需要 5 个字节的存储空间,那么剩下的那两个字节的存储空间就会存储空格字符' '的编码。这也就是说:一旦你确定了 CHAR(M)类型的 M 的值,如果 M 的值很大,而你实际存储的字符串占用字节数又很少,会造成存储空间的浪费。
小贴士: 字符'a'在 ascii 字符集下被编码为 0x61,字符'b'在 ascii 字符集下被编码为 0x62,字符'c'在 ascii 字符集下被编码为 0x63,空格字符被编码为 0x20,所以将字符串'abc'存入采用 ascii 字符集的 CHAR(5)类型的表属性中时,实际存储的字节序列就是:0x6162632020。
# VARCHAR(M)
总结:可变长度字符串类型(+1 或+2 字节)
如果你表中的某个列需要存储字符串类型的数据,而且这些字符串长短不一,那么使用CHAR(M)可能会浪费很多存储空间,VARCHAR(M)正是为了解决这个问题而生的。
VARCHAR(M)中的M也是代表该类型最多可以存储的字符数量,理论上的取值范围是1~65535。但是MySQL中还有一个规定,表中某一行包含的所有列中存储的数据大小总共不得超过 65535 个字节(注意是字节),也就是说VARCHAR(M)类型实际能够容纳的字符数量是小于 65535 的。按照 utf-8 mb4存储,最多 65536/3 个数的字符。🔥
VARCHAR(M)类型占用的存储空间不确定,那系统在读一个VARCHAR(M)类型的数据时怎么知道该数据占用多少个字节呢?答案是:不知道。所以一个VARCHAR(M)类型表示的数据其实是由这么两部分组成:
真正的字符串内容。
假设真正的字符串在特定字符集编码后占用的字节数为
L。占用字节数。
假设
VARCHAR(M)类型采用的字符集编码一个字符最多需要W个字节,那么:- 当
M×W < 256时,只需要一个字节来表示占用的字节数。 - 当
M×W >= 256且M×W < 65536时,需要两个字节来表示占用的字节数。
小贴士: 一个字节占用 8 个比特位,能表示的最大无符号数就是 255,两个字节占用 16 个比特位,能表示的最大无符号数就是 65535。
- 当
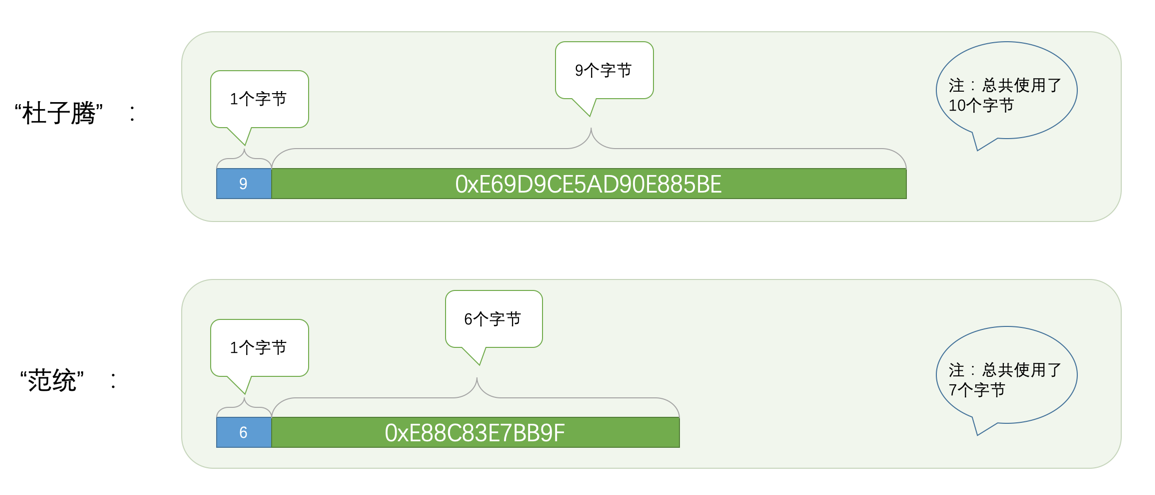
我们还用学生的姓名属性做例子,假设我们给姓名列定义的类型为采用utf8字符集的VARCHAR(5),也就是说M = 5、W = 3,所以M × W= 5×3 = 15,而15 < 256,所以我们只需要一个字节来表示真实数据占用的字节长度就好了。对于'杜子腾'和'范统'这两个字符串来说,它们在utf8字符集下可以被编码成如下的样子(二进制太长了,用 16 进制表示):
'杜子腾':0xE69D9CE5AD90E885BE (共9个字节)
'范统':0xE88C83E7BB9F (共6个字节)
2
那么这两个字符串的实际存储示意图就是这样:
而如果我们给姓名列定义的类型为采用utf8字符集的VARCHAR(100),也就是说M = 100、W = 3,所以M × W= 100×3 = 300,而300 > 256,所以我们需要 2 个字节来表示真实数据占用的字节长度,此时'杜子腾'和'范统'这两个字符串的实际存储示意图就是这样:
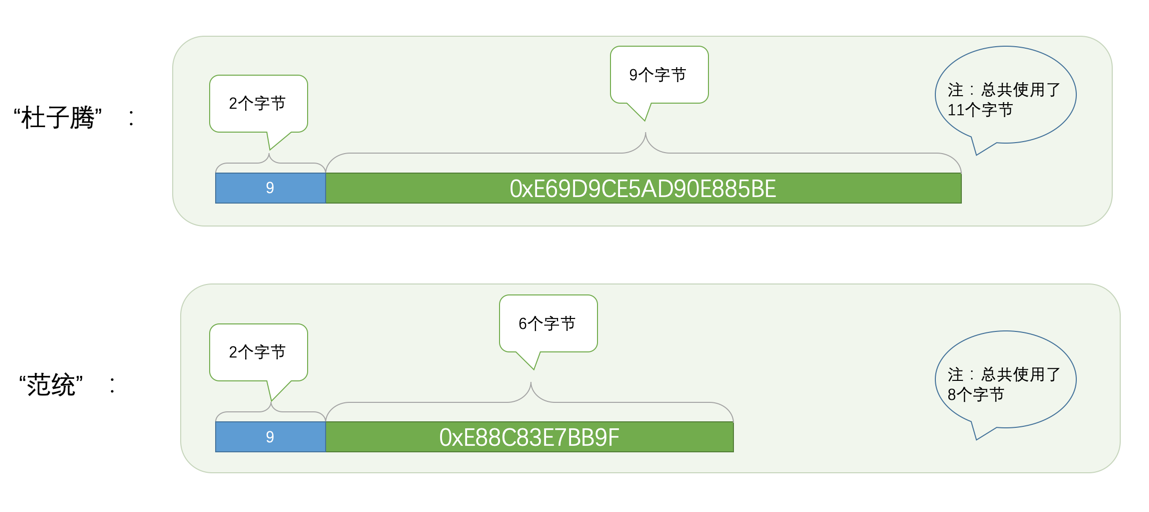
从上边的示例中可以看出,VARCHAR(M)类型占用的存储空间大小随着实际存储的内容变化而变化,假设实际存储的内容占用的字节长度为L,那么整个VARCHAR(M)类型占用的存储空间大小就是L+1或者L+2个字节。所以我们说VARCHAR(M)是一种可变长度的字符串类型。
Oracle 中使用 VARCHAR2 型 ( MySQL 中也有 VARCHAR2 这种数据类型,但并不推荐使用)
# CHAR VS VARCHAR
- char长度固定,不需要考虑边界问题,读写效率高于varchar,适合存储长度固定(不太多)、频繁读写的数据
- varchar长度不固定,但可以通过varchar(m)的方式指定上限,适合存储长度波动、更新不频繁的数据
- char的存储长度不够灵活,而varchar则需要浪费1~2个字节来存储当前值的实际长度,且更新会导致重新计算
没有最完美的类型,只有最合适的类型。比如,当你需要存储手机号码或者身份证号时,用char(11)、char(18)显然更合适。但存储“个人介绍”时,用varchar更好,因为个人介绍的长度是可变的且长度可能很长。
优化:
- 可以采取定长、变长分表
- 常用列与不常用列分表
# 各种 TEXT(或称 CLOB)类型
虽然VARCHAR(M)已经可以存储很长的字符串了,可是有时候还是不够咋办?对于很长的字符串,设计MySQL的大叔们给我们提供了TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT四种可以存储大型的字符串的类型。它们也都是变长类型,也就是说这些类型占用的存储空间由实际内容和内容占用的字节长度两部分构成。
- 因为
TINYTEXT最多可以存储2⁸-1个字节,所以内容占用的**字节长度(不是内容长度)**用 1 个字节就可以表示 TEXT最多可以存储2¹⁶-1个字节,所以内容占用的字节长度用 2 个字节就可以表示。MEDIUMTEXT最多可以存储2²⁴-1个字节,所以内容占用的字节长度用 3 个字节就可以表示。LONGTEXT最多可以存储2³²-1个字节,所以内容占用的字节长度用 4 个字节就可以表示。
因此,变长为 1、2、3、4 字节
不过之前不是有个规定说某一行包含的所有列中存储的数据大小总和不得超过 65535 个字节么?这个规定对这些 TEXT 类型是不起作用的,它们并不在这个规定的限制范围之内。一个表中如果有的属性需要存储特别长的文本的话,就可以考虑使用这几个类型了。
# ENUM 类型和 SET 类型
视角回到我们的学生信息表,性别一列也需要填写字符串,但是比较特殊的一点是,这一列只能填男或者女,填别的字符串就尴尬了!针对这种情况,我们提出了一个叫ENUM的类型,也称为枚举类型,它的格式如下:
ENUM('str1', 'str2', 'str3' ⋯)
它表示在给定的字符串列表里选择一个。比如我们的性别一列可以定义成ENUM('男', '女')类型。这个的意思就是性别一列只能在'男'或者'女'这两个字符串之间选择一个,相当于一个单选框~
有的时候某一列的值可以在给定的字符串列表中挑选多个,假设学生的基本信息加了一列兴趣属性,这个属性的值可以从给定的兴趣列表中挑选多个,那我们可以使用SET类型,它的格式如下:
SET('str1', 'str2', 'str3' ⋯)
它表示可以在给定的字符串列表里选择多个。我们的兴趣一列就可以定义成SET('打球', '画画', '扯犊子', '玩游戏')类型。这个的意思就是兴趣一列可以在给定的这几个字符串中选择一个或多个,相当于一个多选框~效果就像这样:
| 学号 | 姓名 | ··· | 兴趣 |
|---|---|---|---|
| 20180101 | 杜子腾 | ··· | '打球', '画画' |
| 20180102 | 杜琦燕 | ··· | '扯犊子' |
| 20180103 | 范统 | ··· | '扯犊子', '玩游戏' |
| 20180104 | 史珍香 | ··· | '画画', '扯犊子', '玩游戏' |
综上所述,ENUM 和 SET 类型都是一种特殊的字符串类型,在从字符串列表中单选或多选元素的时候会用得到它们。
# 二进制类型
# BIT 类型 🔥
有时候我们有存储单个或者多个比特位的需求,此时就可以用到下边这种类型:
| 类型 | 字节数 | 含义 |
|---|---|---|
BIT(M) | 近似为(M+7)/8 | 存储 M 个比特位的值 |
其中M的取值范围为1~64,而且M可以省略,它的默认值为 1,也就是说BIT(1)和BIT的意思是一样的。
MySQL是以字节为单位存储数据的,一个字节拥有 8 个比特位。如果我们想存储的比特位个数不足整数个字节,那么MySQL会偷偷的填充满,比方说:
BIT(1)类型仅仅需要存储 1 个比特位的数据,但是MySQL会为其申请(1+7)/8 = 1个字节。BIT(5)类型仅仅需要存储 5 个比特位的数据,但是MySQL会为其申请(5+7)/8 = 1个字节。BIT(9)类型仅仅需要存储 9 个比特位的数据,但是MySQL会为其申请(9+7)/8 = 2个字节。
据此来说,也没有必要对类似 status 使用该类型
# BINARY(M)与 VARBINARY(M)
BINARY(M)和VARBINARY(M)对应于我们前边提到的CHAR(M)和VARCHAR(M),都是前者是固定长度的类型,后者是可变长度的类型,只不过BINARY(M)和VARBINARY(M)是用来存放字节的,其中的M代表该类型最多能存放的字节数量,而CHAR(M)和VARCHAR(M)是用来存储字符的,其中的M代表该类型最多能存放的字符数量。
# 各种 BLOB 类型 ☠️
TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB是针对数据量很大的二进制数据提出的,比如图片、音频、压缩文件啥的。它们很像TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT,不过各种BLOB类型是用来存储字节的,而各种TEXT类型是用来存储字符的而已。
- tinyblob(2^ 8-1B)
- blob(2^ 16-1B)
- mediumblob(2^ 24-1B)
- longblob(2^32-1B)
小贴士: 对于比较大的二进制数据,比方说图片、音频、压缩文件什么的,通常情况下都不直接存储到数据库管理系统中,而是将它们保存到文件系统中,然后在数据库中之存放一个文件路径即可。
# 注意
小贴士: MySQL 其实可以大致被分为 server 层和存储引擎层,server 层用来做一些通用的逻辑,存储引擎层负责具体的数据读取和存储,针对不同的使用场景设计了许多种不同的存储引擎。各种数据类型在 server 层的格式是一致的,本文对各种数据类型占用存储空间的分析也是基于 server 层的,不同的存储引擎针对不同的数据类型可能有其特定的实现,我们就不单独唠叨了。在《MySQL 是怎样运行的:从根儿上理解 MySQL》这本书中介绍了 InnoDB 存储引擎对于 VARCHAR 和 CHAR 格式的具体实现,有兴趣的小伙伴可以到该书中查看。 当然,这段话是给有经验的小伙伴看的,如果大家压根儿没听说过 server 层、存储引擎的概念,请自动忽略这段话,请自动忽略这段话,请自动忽略这段话!
# 常用的字段列类型 🔥
- 身份证号由于最后一位可能是 X,所以就归为字符串了